
0×01 YY
眨眨眼。支付婊这个刷脸的功能估计让大家都给玩坏了,不过支付宝竟然又出了一个让我沉迷于其中,无法自拔的玩物,没错,就是这个玩意儿:
好汉!你能过几关!不过对不起,在下脸盲!
说到正经处,我必须想办法,支付宝竟然用此等技术来逗我,我岂能善罢甘休!待我修炼成果,再和你决一死战。
之前看过一篇文章,支付宝刷脸支付功能,美图秀秀,就是运用Face++公司的人脸识别技术。心里一想,这下有戏了,打开官网一看
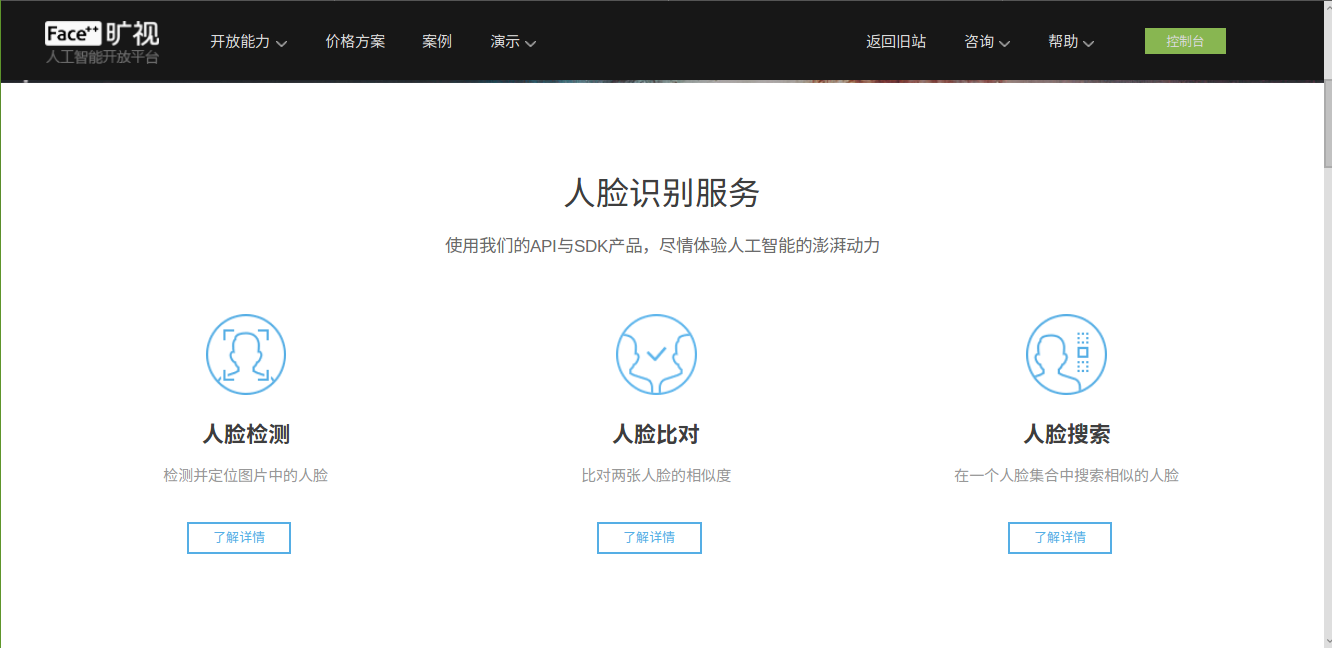
啊哈,“免费接入”瞬间映入眼帘,注册帐号—进入console—阅读API文档–获取API-Key—开始我的python之旅了。
0×02 思路
先遍历所有照片并保存在本地,将的图片以(ID.name.jpg)的形式命名,调用delectAPI,将返回的face_token,和ID,name一并录入MYSQL数据库,在进行比对的时候,调用compareAPI,将显示的图片与数据库录入的图片信息进行比对,对返回信息进行处理,返回置信度最高的那位,想想就来劲。
那么问题来了,难道仅仅局限于图片的识别吗,不,我们不会这样的,我们是有志的青年,怎能就这么得到满足,对了还有摄像头,进行实时的人脸识别,说不定哪天,美女从你身边走过,你却浑然不知,所以,那就开始作呗!
0×03 环境搭建&目录构建
环境搭建:
Ubuntu 16.04 LTS:其实其他的版本也可以,这里要求不是太苛刻
python 2.7:使用的是python2.7,毕竟人家还可以在支持10年,就将就的先用着,
MySQL:使用的是LAMP环境,百度搜索LAMP环境搭建,一大堆教程,
MySQLdb:python下的Mysql包
sudo apt-get install python-pip
sudo apt-get install libmysqlclient-dev
pip install mysql-python
OpenC+V 3.2.0——-关于版本的使用当然是越稳定越好,关于如何安装OpenC+V,这里就简单的说一下下,毕竟没有它,后面的代码也运行不了,
安装的依赖包:
sudo apt-get install build-essential sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
从github上下载最新的源码:
git clone https://github.com/opencv/opencv.git #这个是最新的OpenC+V 公布在github上的代码git clone https://github.com/opencv/opencv_contrib.git #这个里面有一些模块,比如freetype,face,等需要用到
PS:官网的教程里面将两个包分开进行编译,但是里面的许多包我们确实用不到,所以,最好的办法,就是将./opencv_contrib/moudles/freetype和face文件直接复制到./opencv/moudles/下,经实践检验—-可行!
cd ~/opencv mkdir releasecd releasecmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local .. make -j4 #这里的-j4代表怎么说好呢,反正越大,编译的速度越快,我最大用过-j8,但我的电脑只是4核! sudo make install
PS:这里说一下了。在运行cmake的时候,需要下载几个文件,比如ippicv_linux_20151201.tgz,竟然需要挂代理,天哪,所以我就挂了一个,关于如何在ubuntu上安装shadowsocks科学上网,我的博客也有写过 点我
到此,环境方面已经搭建的差不多了。
实在抱歉。没能在代码中写上任何注释信息。因为我的编辑器(sublime_text 3)真心无法在里面输入汉字,
现在来看一下该FRT的工作目录,如图
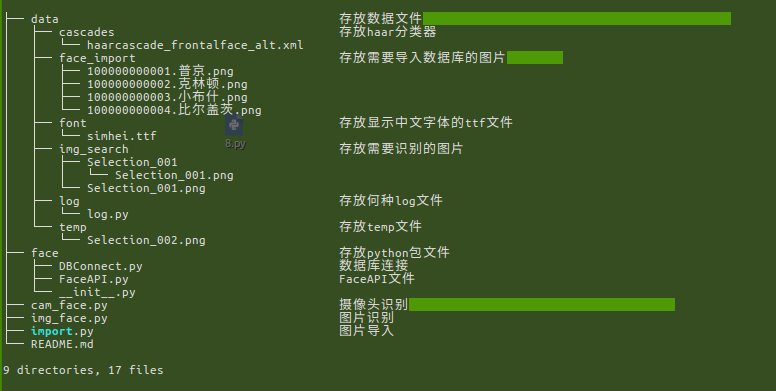
0×04 代码构建
1:faceAPI.py #API的调用
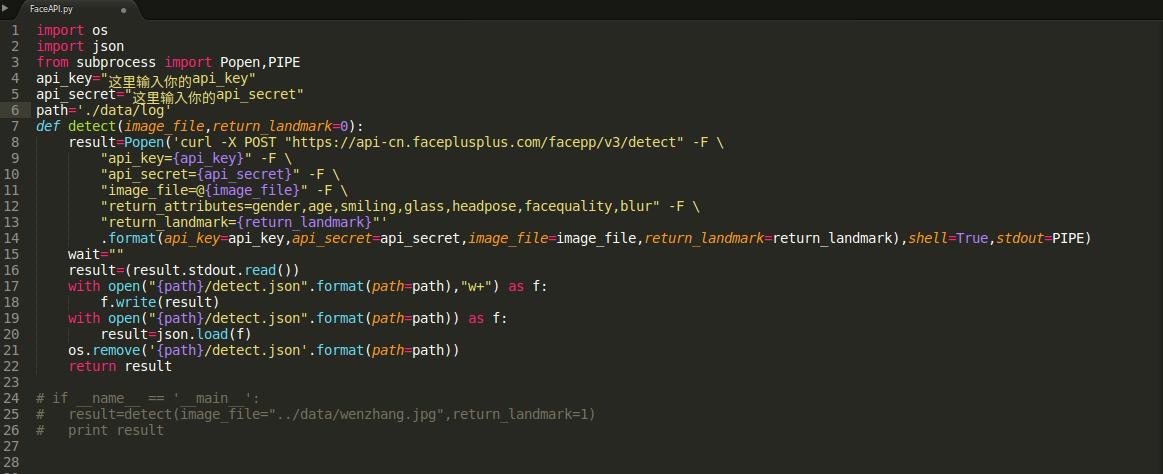
这里为了方便以后进行调用,特意的将FaceAPI写成包,放在创建的face目录下,
FaceAPI中包括delect(面部识别),analyze(面部分析),compare(面部比对),search(面部搜索),faceset(创建面部集合)等,因为官方文档给出的就是采用curl -X POST方式进行数据上传和返回,所以就直接在导入标准库的subprocess包,在python中调用curl,当然还有更好的方法,比如用python标准库里的urllib2里的POST进行上传.但咱们不这是为了省事嘛!返回结果为JSON的格式,为了方面进行调试,特异的将Json写log中,当出现错误的时候,可以查看log的内容,这些JSON数据在下面用到的时候再进行处理
2:DBconnect.py #数据库的连接

这里将数据库的连接也写在了包里面。主要为了方便移植,基本上下载我的代码上,修改一下这里,基本上就可以用了
在host里填写数据库的地址,port迷人都为3306,user为数据库用户名,passwd为数据库密码,db为数据库的名称,charset为数据库编码方式,为了能让表显示中文
3:import.py #人脸数据的导入
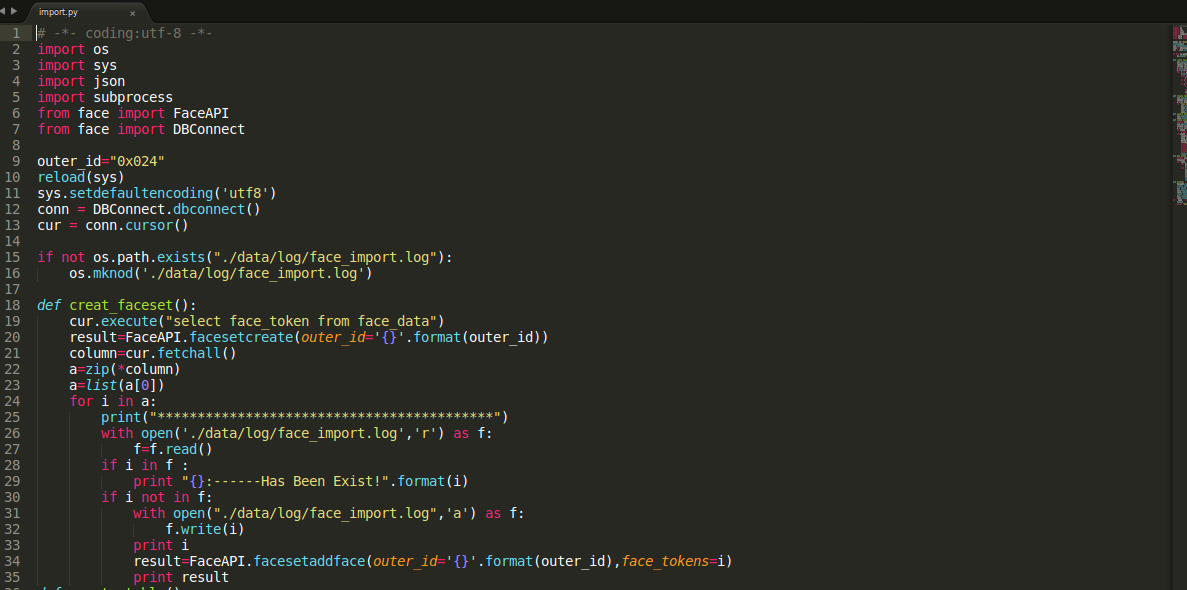
这里的话。首先要创建一个的faceset(人脸的集合),调用FaceAPI.facesetcreate()进行创建,传入一个outer_id.也就是你要导入这批人脸的集合的唯一标识,这个值是唯一的。为了当你再次运行import.py时候,防止图片多次的重复导入到数据库中或者多次进行faceaddface(),将每次导入的图片文件名写进到log中,这样就可以减少了服务器的压力(虽然这点微不足道,但是毕竟免费用人家的嘛),如果图片不存在的话,将调用FaceAPI.facesetaddface(),将读取到的脸添加到到faceset中
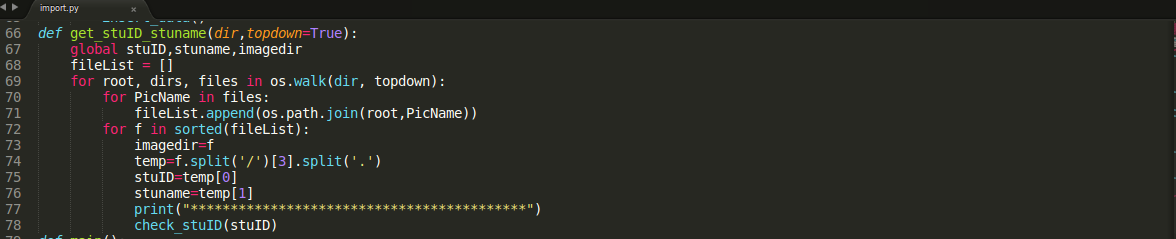
这个要多说一点,首先,将要导入的图片存放才./data/import_face/下,当然图片要命名为,”ID.name.jpg”的任何格式,毕竟我的数据库在进行创建的时候就是这样进行数据录入的,然后调用os.walk()对路径进行分割,append()进行连接。
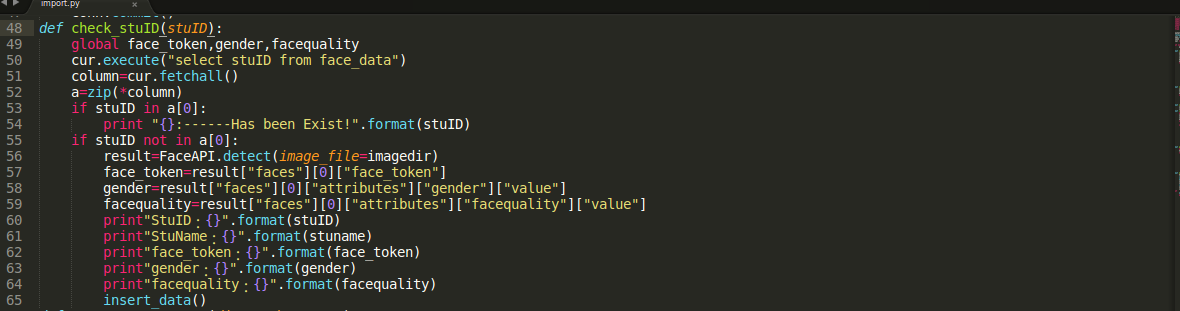
这一步就是对调用detect()返回的json文件进行数据的整理,分别提取其中的face_token,gender,facequality的value,当然也可以返回其他的信息,比如gender,age,smiling,headpose,facequality,blur,eyestatus,ethnicity等。
PS:这里有个坑,因为我数据库创建时候,写的是face_data(stuID varchar(12),也就是说,你如果命名的ID小于12位的话,那么他前面的数字全部为随机的,所以当调用check_stuID()的时候,if stuID in a[0]:永远为false

这一步就是要将所有的数据写入到数据库中,因为之前,都将ID,nameface_token等信息进行的全局global的声明。所以这里可以直接进行写入,需要提醒的是,每进行一条sql语句,都与要跟一句 conn.commit()才可以将sql语句进行提交
python import.py
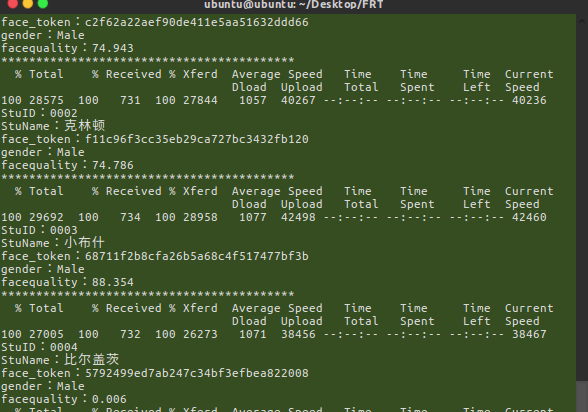
最后运行 就可以看到图片信息在慢慢的导入到数据库中
4:img_face.py #检测图片中所有人的面部
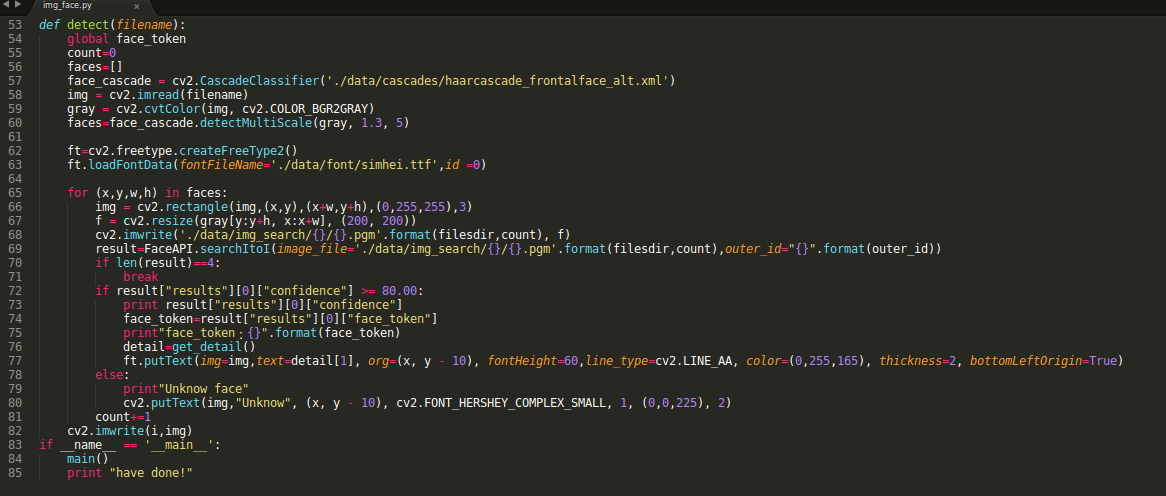
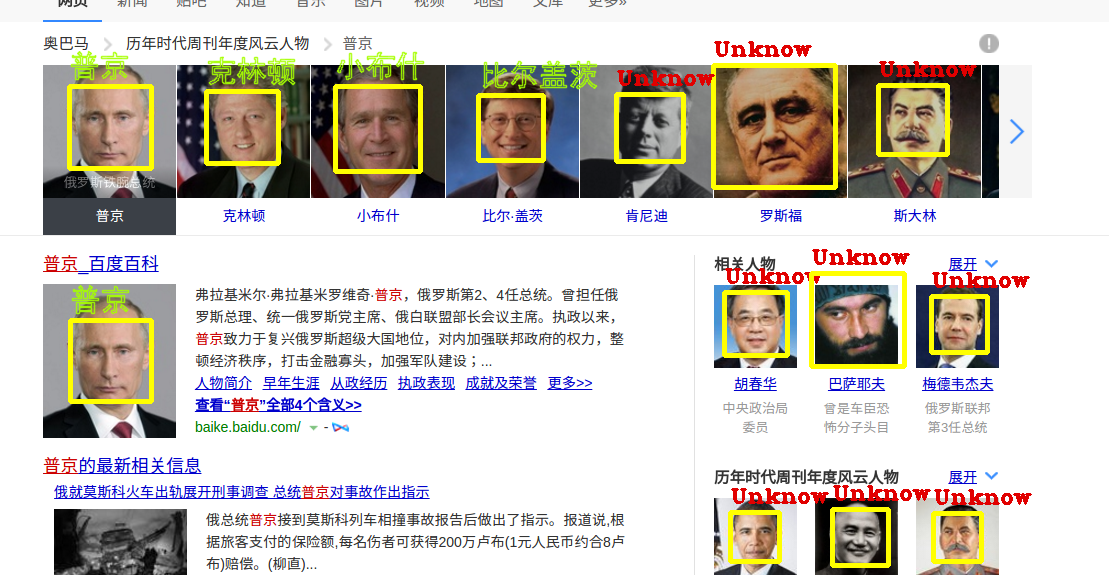
这里就要用到一些OpenC+V的内容了,其实不用太去深刻的学习OpenC+V,毕竟我们仅仅能使用到OpenC+V的很小一部分,而这一部分恰恰正是经常用到的,首先加载cv2.CasacdeClassifier选择器,接着加载图片放在img_search目录下的图片,将起转化为灰度,据说机器对灰度图片的识别效率更高,因为cv2.puttext对中文的支持不够友好,所有这里调用了freetype库(开始已经安装过),从而可以让脸部的框框显示中文,在for循环中,每找到一个面部,就会调用cv2.rectangle(),将面部用黄色的方框标记出来(当然你也可以尝试其他颜色,这里只需要修改BGR(0.255.255)的值就可以),并命名其为*.pgm,写入到/data/img_search/文档下,然后调用FaceAPI.seaechItoI(),让.pgm图像与faceset集合进行比对,并且返回faceset集合中与之置信度最高的face_token,这里设置了以下阀值,如果置信度不高于设定的80.00的话,就会打印“Unknow Face”,
关于img_face需要介绍就这些,下面来运行
python img_face.py
(不错,看着还可以,)
5:cam_face.py #摄像头实时识别(可多个脸)
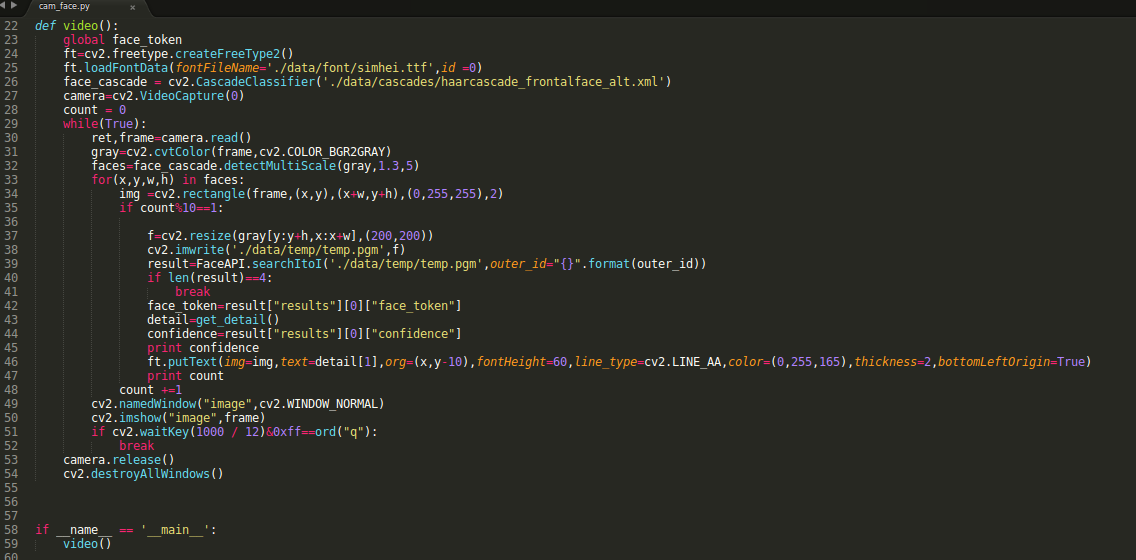
这里和图片识别原理差不多,只是OpenC+V将视频的每一侦都进行了识别,这样的话,因为每一帧都需要调用一下API进行上传,所以会出现画面卡顿的情况,不过还好,能接受
当然,人脸越多,上传的时间就越长,卡顿的就越厉害,反正我现在还没有找到解决办法,
下面来运行,
python cam_face.py #羞羞

0×05 实战
下图为此实战的工作目录,所以和之前FRT不再一个目录下,

迫不及待的我啊,已经无法按奈主内心的机动,不多说,直接贴代码,上图伺候
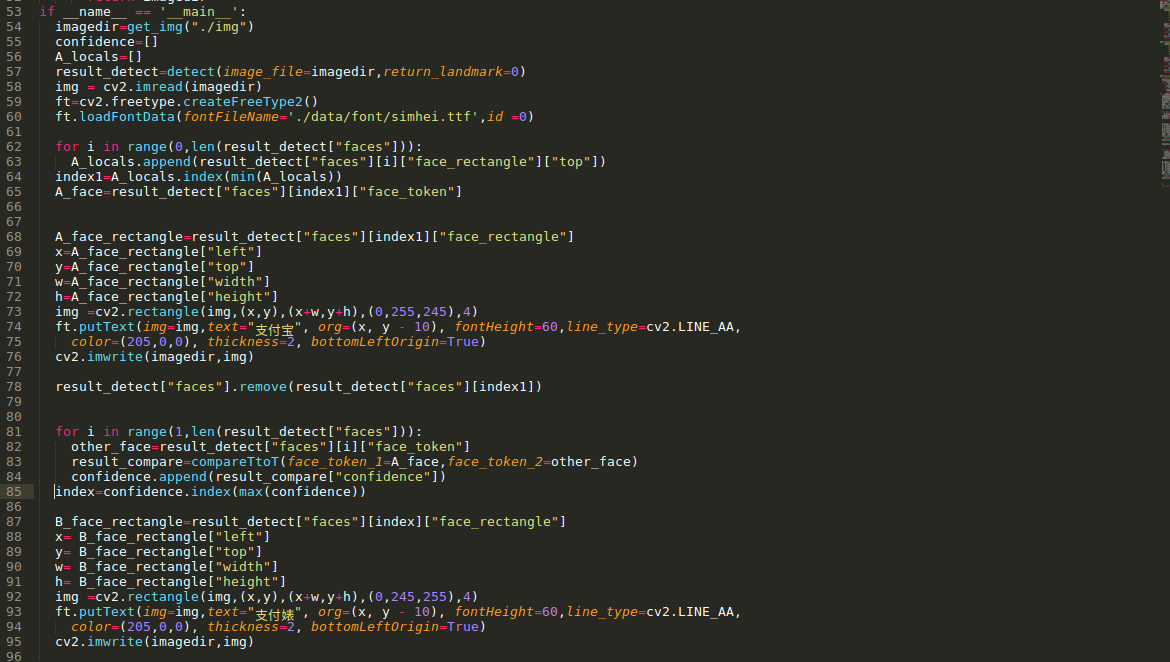
首先,用cv2.image()将图片读取进来
。。。。。。。
此处省略300字
。。。。。。。。
代码部分讲解完毕,下面来执行
python alimemeda.py #运行完毕后,打开./img目录下的图片,你将会看到如下的显示
这下终于可以把支付宝和支付婊分的一清二楚了,不过嘛,好像他们并不怎么像啊,估计是出现了幻觉,对一定是幻觉,。
^_^,终于完成了我的报复。
0×06 github代码下载
所有的代码全部上传到了的我的github上,大家可以在这进行下载运行前:
1:需要将./face/FaceAPI.py中的api_key和api_secret换成你的
2:需要在搭建的MYSQL中搭建一个FRT数据库,并且事先创建一个任意表
3:需要将./face/Dbconnect.py中的数据库信息换成自己的
其实之前,也有在本地,利用OpenC+V的深度学习来对人脸进行识别,但是识别率真的很低,所以在这,我没有将这些代码给码出来,而是直接发布在我的github上。当然这也不妨你们去阅读也修改
0×07 感谢
特别感谢我的网友们,是你们给予了我动力,坚持将自己的想法变成现实
特别感谢我的学校,给了我这么多的课余时间来敲这些代码(这学期的课实在是少的egg疼)
特别感谢我的家人,给了我这么好的条件,让我在这里学习,学习,学习
最后感谢我自己,有这么大的毅力将这些代码写下来,即使明天要考试,0.0!
谢谢大家 !么么哒!
 微信扫一扫打赏
微信扫一扫打赏







